

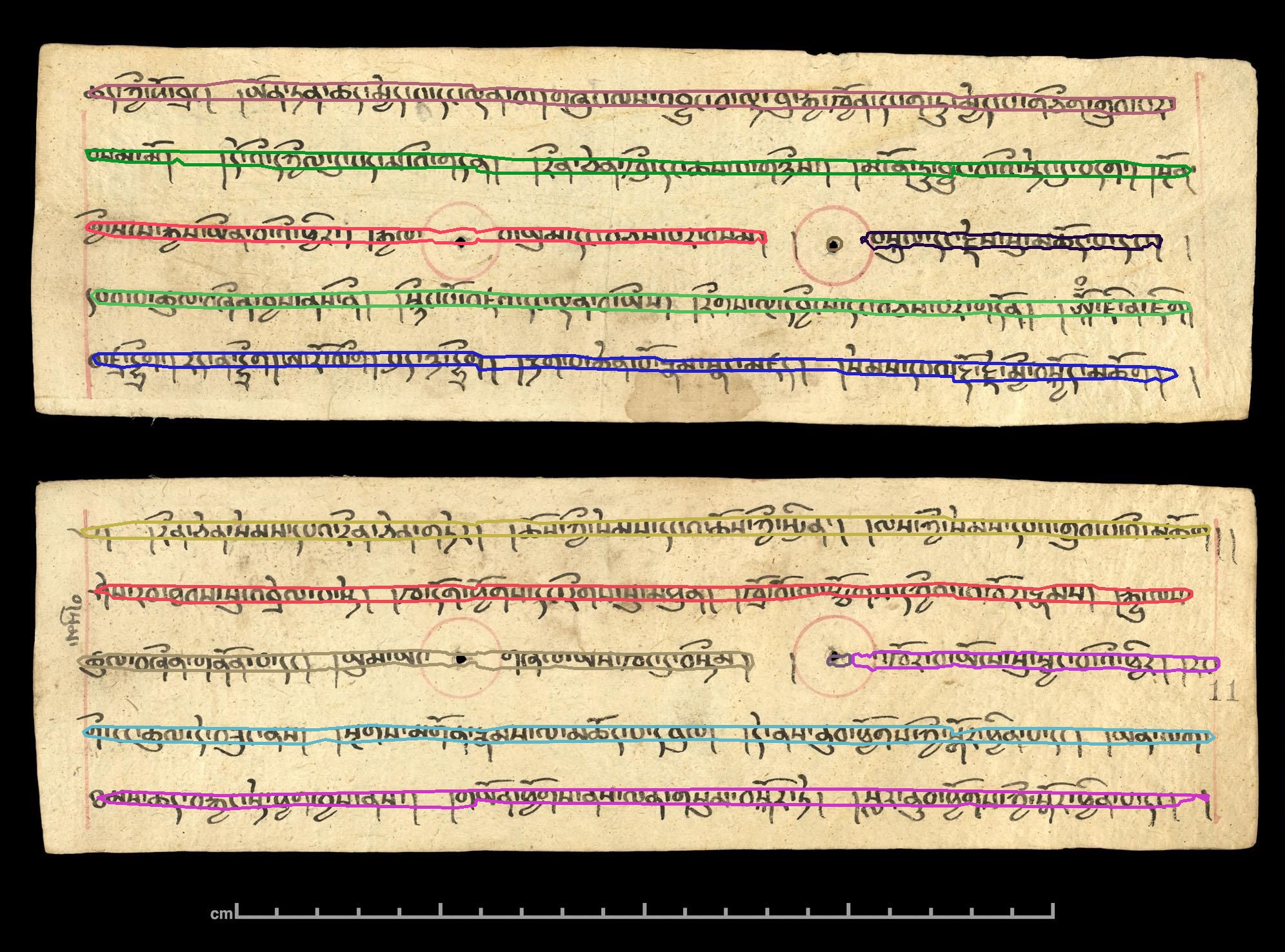
Example of line detection in a handwritten manuscript from Dunhuang (from the International Dunhuang Program, British Library, view the full text here)
The Buddhist Digital Resource Center is proud to announce an exciting project that will contribute a powerful new app and millions of pages of primary materials to Tibetan Studies. Our team is developing a desktop application for optical character recognition (OCR) of Tibetan scripts, addressing a critical need in the academic and preservation communities. Our users around the world have been requesting a tool like this for years, as at present there is no reliably accurate and free OCR service available for Tibetan that can accurately recognize all of the major Tibetan scripts and text types, while popular commercial options such as Google Cloud Vision have significant limitations.
BDRC has made crucial breakthroughs in Tibetan OCR through its in-house expertise and fruitful partnerships with others in this field. As a result, later this year we will launch a free application for laptop and desktop computers that can convert the Tibetan writing captured in BDRC scans into a format that can be used in word processors and other apps for searching, editing, re-publishing, and so on.
By combining Tibetan paleographic expertise with cutting-edge machine learning techniques, we aim to 'unlock' the writing embedded in scans of manuscripts to facilitate large-scale searching, information extraction, machine translation, and the further development of artificial intelligence for Tibetan. This will help translators, lamas, and scholars, and, ultimately, make the BDRC archive much more suited for 21st century technologies.
The Challenge of Tibetan Script Diversity
Tibetan, with its rich literary tradition spanning over a millennium, presents unique challenges in the realm of digital preservation and text recognition. Tibetan has been written in a multitude of handwriting styles and scripts throughout its history. While there is only one Tibetan alphabet and early in its history there were efforts to standardize Tibetan spelling and grammar, the scripts do vary significantly and in many cases native readers might have difficulty reading certain scripts from regions or time periods that are distant from their own. Surprisingly, until now the diversity of Tibetan scripts found in surviving manuscripts have not been systematically documented in traditional or scholarly literature.
BDRC's archive of Buddhist literature holds around 4 million images of manuscripts in various handwritten scripts. There is no better resource for the rigorous study of the history and artistry of Tibetan scripts. Unfortunately, current solutions, such as Google Cloud Vision and Transkribus, are not able to "read" most of the unique and historically significant texts in the BDRC archive. BDRC is, therefore, pursuing open source, freely available solutions to improve on existing models. By developing custom datasets, training specialized models, and implementing automatic style detection, the BDRC app will make previously inaccessible texts readable and searchable.
 Examples of different Tibetan scripts
Examples of different Tibetan scripts
Addressing the Challenges of Tibetan OCR
To address these complex challenges, BDRC has embarked on a multi-faceted approach combining Tibetan paleographic research, machine learning techniques, and innovative software development.
1. Script Classification and Documentation
In the first quarter of 2024, the BDRC team launched a project to create a detailed map of the different styles used in historical Tibetan manuscripts. Tibetan script specialist Pentsok W. Rtsang conducted a comprehensive and evidence-based overview of Tibetan fonts, developed a list of major Tibetan calligraphy styles and scripts, and documented standard grid systems for Tibetan letters and their variations.
This original research culminated in a hierarchical classification of Tibetan scripts comprising three levels:
- Level 1: Four broad types – Uchan, Ume, Other Scripts, and Mixed Scripts, encompassing 20 etic classifications for training OCR and HTR models.
- Level 2: 48 detailed Tibetan scripts found in literature, recommended for use in the BUDA library's taxonomy.
- Level 3: A catalog of 108 Tibetan scripts with identifier numbers and samples.
This classification system enables, for the first time, a systematic categorization of common Tibetan scripts in manuscripts. Pentsok W. Rtsang is currently working on classifying an additional 1,150 volumes of manuscripts, writing script descriptions, and preparing to publish the results in a peer-reviewed international journal of Tibetan Studies.

A woodblock printed text from the works of Tsongkhapa, illustrating the process of creating training data for OCR.
2. Dataset Creation and Model Training
Up to now BDRC has mostly relied on Google Cloud Vision for recent publications that use computer fonts. Apart from this and some very recent projects focused on selective handwriting styles, a broad approach to OCR for Tibetan was unattainable. (Two Ume style models are available in the Transkribus ecosystem, which were created by a research project in Vienna.) To enhance OCR capabilities for Tibetan scripts for a wider audience, our tech team is in the process of creating a user-friendly, offline desktop OCR application. Eric Werner of the University of Hamburg has taken the lead on training an OCR model and a line detection model on carefully curated datasets.
Key milestones in our development process include:
- Developing a line extraction pipeline and detecting individual layout elements on a wide range of materials, including manuscripts from Dunhuang dating back as early as the eighth century, xlyographs of various provenance, as well as modern printed books
- Ongoing expansion of OCR datasets and retraining of models, which are published on HuggingFace
- Conducting initial tests on a script classification model
- Creating and training OCR models for handwritten styles
- Developing small datasets for internal testing of the OCR desktop app
- Evaluating a state-of-the-art language model for OCR post-correction supplied by Sebastian Nehrdich from U.C. Berkeley.


Examples of line detection on texts from the Matho collection of ancient manuscripts from Ladakh, photographed by the Tibetan Manuscript Project Vienna. Read more about the Matho Collection here.
3. Applying the Classification of Scripts to BDRC Scans
The BDRC team approached script classification from two perspectives as a supervised learning objective: firstly attempting to train a classifier based on a comprehensive dataset covering 19 identifiable Tibetan script types, and secondly using a simplified dataset accounting for visual similarities, hypothesizing that OCR models can learn common features from 'similar enough' scripts.
In order to quickly process large collections, the team trained networks using page-level image tiles that encompass multiple lines. This approach enables rapid identification of the primary script type on a given page. In a second step we aim to add fine-grained script classification on the line-level to account for script changes in cases of multilingual works, interlinear notes or simple script changes within or between lines.

Finding a way to handle rare Tibetan letter stacks is another machine learning challenge.
4. Collaboration and Dataset Expansion
Our project has benefited greatly from collaborations with other organizations. New datasets became available thanks to annotation support from OpenPecha, a collaborative involving Monlam AI, BDRC, and others. These datasets include:
- Lhasa Kanjur dataset (~ 160.000 line samples)
- Lithang Tenjur dataset (~ 500.000 line samples)
- Derge Kanjur dataset (~ 800.000 line samples)
- Ume datasets created from high-quality scans provided by BDRC
- Norbuketaka dataset (~ 2.2m line samples of modern type-set)
- A new "GoogleBooks" dataset consisting of 100 post-processed Google-OCR books
- The "KhyentseWangpo Dataset" comprising approximately 13,000 line samples from a modern type-set edition
- A "8th Karmapa Dataset" containing approximately 30.000 reviewed woodblock line samples from miscellaneous writings of the 8th Karmapa

Examples of line detection on a handwritten text from the Tabo Collection.
Technological Innovations
In previous blog posts we have featured ways in which BDRC is using AI to modernize the archive and facilitate deeper access to the content of the manuscripts; see for example here and here. BDRC's OCR system also incorporates several cutting-edge technologies, including the following:
- Deep Learning Model Deployment via ONNX: Recent advancements have made it possible to easily install and run these models on various devices, making the technology more accessible.
- Multiple OCR Architectures: We're experimenting with various Deep Learning architectures such as CRNN, Easter2, and TrOCR to determine the most effective approach for Tibetan script recognition.
- Language Models: We aim to optionally incorporate a state-of-the-art (ByT5) language model into the OCR pipeline to improve the OCR accuracy.
- Script Classification: Our approach to script classification allows for rapid processing of large collections and lays the groundwork for more nuanced multi-script detection on individual lines in the future.

Future Plans and Collaboration Opportunities
The BDRC team is currently focusing on two key areas: firstly training OCR networks with Uchan and Ume scripts using multiple architectures, among which is a unified Uchan model with 4.4 million samples, and secondly developing script classification models. All of this work will lead to the planned release of a Beta version of the OCR app towards the end of this year, with an end-to-end workflow for offline public use.
In parallel BDRC is currently preparing the systematic pre-processing of its archive using these latest OCR models. Like all AI projects, however, this requires team work, and we invite collaboration from researchers, developers, and institutions working in related fields. We are currently working with an international group of experts around the world, including Eric Werner, Pentsok W. Rtsang, Tashi Tsering and others at Monlam AI, Sebastian Nehrdich of Berkeley Artificial Intelligence Research, and the team at the Tibetan Manuscript Project Vienna.
If you see potential to work with BDRC, on funding applications or particular areas of activity, please get in touch. Two key areas for cooperation are expanding and refining our datasets, and post-processing and error correction of the OCR output. The development of language models specifically tailored for Tibetan texts, and the integration of BDRC's OCR system with other digital humanities projects and platforms are also potential areas to explore.
This project has the potential to unlock vast repositories of knowledge previously inaccessible to digital analysis, opening new avenues for research and discovery in Tibetan studies. Moreover, the methodologies and technologies developed in this project could serve as a model for similar efforts in other languages with complex script systems.
We're excited about the possibilities this project opens up and look forward to collaborating with the wider academic and tech communities to further refine and expand our OCR capabilities. Together, we can ensure that the rich literary heritage of Tibet is preserved and made accessible for generations to come.
For more information on how to get involved or to discuss potential collaborations, please contact us at help@bdrc.io – thank you!
Sorry, the comment form is closed at this time.